Introduction
It often seems like the podcast adtech industry spends the majority of its time trying to fit a square peg in a round hole.
I get why. We’re chasing this goal of attracting the major brands and advertisers from other media channels as we continue to create more content and therefore more ad inventory within our own media channel. But the mistake we’re making is trying to dress podcast advertising up to look like other digital advertising channels. The truth is, those channels are always going to get more data than podcasting, especially client/listener-side data.
And that’s a-ok.
There are other advertising channels with the same—or worse—data limitations as we see in podcasting. In 2020, the social media influencer marketing space hit $10bn, a form of advertising with no third-party metrics and no client-side data available to advertisers, yet all we focus on is how podcast advertising stacks up against digital advertising.
Instead of wasting yet another year whining about not receiving mobile device IDs or client-side metrics, let’s gear up to do more with what we have, because we’re honestly not pushing the needle far enough.
Data Processing Agreements
Privacy is the name of the game going forward, and with that, podcast players, publishers, hosting platforms, tracking vendors, and advertisers absolutely need to lock down who owns what data and how the data can be accessed.
When I covered privacy in the podcast advertising space before, I focused on two classifications that seem to be recurring in all of the incoming and existing legislation: controller and processor.
The general idea is that the controller ultimately owns the data while the processor handles the data on behalf of the controller. For the publisher-to-hosting platform relationship, the controller would be the publisher—they own the data— and the hosting platform would be the processor, because they handle the data on behalf of the publisher. At the risk of beating a dead horse, the publisher owns their episode download data but it’s the hosting provider that’s responsible for storing the data.
Where it gets a bit murky is when other partners are involved. Are podcast players controllers because they maintain the direct relationship with the users of their app? Or are they processors because they provide that data to the publisher by way of the hosting platform? The major podcast apps would likely say the former, while the smaller apps would say the latter.
What about who owns the data processed by a tracking vendor? Would that be the entity that owns the account relationship with the vendor (publisher or advertiser)? Or is it the publisher because it’s against their inventory that the tags are being run?
These aren’t easy questions to answer, and ultimately there is no right answer. But it’s absolutely critical that every company in this space understand who owns and is ultimately responsible for the data collected from their engagement in podcasting, whether advertising or not.
Much of the reporting offered by podcast hosting platforms is really middle of the road. It hits all the important metrics like downloads, listeners, ad impressions, and some sort of breakout of what they know about the listeners. But there’s so much more room to grow here. If you’re willing to roll up your sleeves and get hands-on with the data, you can get some real insights. Like:
Learning From IP Address
There’s a lot more we can do with IP address in podcast advertising than we currently are doing.
For starters, we could reduce waste on geotargeted campaigns. Home and business IP addresses have an accuracy radius of 10km vs cellular IP addresses with a 200km radius. By separating the two, publishers and networks could absolutely offer true hyper-local geotargeting and the ability for advertisers to choose whether they want to target downloads at their home, office, or both, without wasting impressions on listeners that could easily be three hours away from whatever they’re advertising.
Or on a more specific level, companies like Megaphone and ART19 could avoid serving demographically targeted campaigns to less accurate download requests. There’s truly no value in associating demographic data with a cellular download request. But without being able to identify what type of connection the download came from, these hosting providers are blindly looking for a match instead of only looking for accurate matches.
If they were identifying the connection type, they’d move beyond just looking for a match with their demographic partner (in these instances, Nielsen and Claritas). Instead, they could filter out all business and cellular requests, making their results more accurate. Shifting to this approach would also better protect the interest of the publisher and advertiser. It probably doesn’t hurt that listeners would have a better ad experience than the equivalent of trying to target one single person with a billboard at the mall.
Enabling a publisher to view all of their metrics through this lens, split by each connection type, would add substantial value to each of the metrics currently reported by hosting providers. It gives publishers that much more control to confidently represent their numbers.
Get More Out of Useragent
I’m comfortable saying that every hosting provider worth your time has a decent grasp on extracting value from a device useragent. Most hosting providers can give you a breakdown of device types, operating systems, and specific apps listeners are using. And while every hosting provider should absolutely step up their game with RSS useragent detection, there is still so much more we can do with useragent.
Here’s a great example: Stephanie Fuccio of Podcast Review Day wanted to somehow quantify the benefit of listing her podcast on every index. Great question, and one that we couldn’t easily find any reporting on. But all the tools are 100% in the hands of the podcasters or their hosting platforms to answer this.
Each podcast player out there pulls from a specific index. By identifying which players relate to which index, the downloads associated to those indexes could be aggregated. We’re already able to see the distribution of podcast downloads by podcast apps, with this way of thinking we could easily see it across the different indexes.
Hosting platforms could also utilize this data to tell us more about the apps themselves. With the amount of downloads they have access to, it becomes trivial to identify how quickly after an episode is published does each app start downloading it for their subscribed listeners. Once they know that, hosting platforms could start displaying estimated subscriber counts for their publishers, giving podcasters one more interesting metric.
A conversation with Erica Mandy of the NewsWorthy led to another great idea of how we could be getting more out of this dataset. By using the IP address and the trends identified above, along with filtering out cellular requests as discussed in the IP section, it would be very possible to track per-episode growth (or decline) of unique subscribers, something hosting providers aren’t currently tracking. While not 1:1 accurate, there’s absolutely room to make estimates here, which is honestly better than what we’ve got available to us today.
Aggregated Listener Data
We need to stop overlooking the value of the data that Apple, Spotify, and Google actually do share with podcasters.
In each of the podcaster dashboards provided by those services, different metrics are presented. Spotify seems to get the most granular, layering on demographic data like age and gender. But all three platforms identify something akin to an active listener count. What’s fantastic about this data is that it’s app-based data. It’s not the IAB unique listener count methodology, which bases all of its logic off of at least 60 seconds of an episode being downloaded. App-based data actually shows the exact moment where the listener stops the episode. This data aggregates the actions of all the users of that app that listen to an episode or show, resulting in much more rich data than just the hosting provider’s reporting of requests for download.
I think this data gets dismissed because it doesn’t tie directly back to the hosting platforms 1:1 data, nor does it cover every download a podcast gets. But it doesn’t have to. I’m not a data scientist, but I’m comfortable saying that between the three partners listed, with Amazon notably absent at least for now, you’ve got a big enough percentage of your podcast’s downloads on at least one of them to have a statistically relevant sample.
So if Spotify says your show skews more female than male, or Apple states that on average your audience listens to 70% of your episodes, you can safely apply that sample size appropriately across your entire show, giving you a strong understanding of how listeners actually engage with your content.
Outside of providing another great metric that advertisers would love to see yet generally aren’t privileged to, it could allow for some really interesting thinking outside of the box. Juleyka Lantigua-Williams of Lantigua Williams & Co. wrote an interesting piece for NiemanLab about how downloads are a flawed metric for podcasting (spoiler: she’s right). But the more intriguing idea is where she suggested that CPM could be more accurately tied to average listen-through rate, increasing or decreasing in value based on how much of the audience listens past where the ad is placed.
While I personally think post-roll is bullshit, if you’ve got a high enough percentage of your audience that listens all the way to the end of your show, you realistically could justify the value post-roll brings to your show. So if a show has a 90% listen-through rate where the industry average sits somewhere in the 60’s, backing it up with data is an easy way to justify the value a post-roll would bring to an advertiser.
Wrapping It Up
We need to come to terms with the fact that because podcasting is open and also due to the massively positive push for more consumer privacy, we’re realistically not going to get the granular listener level data that advertisers familiar with other media channels are clamouring for. But we don’t need it. Advertisers are spending plenty of money on channels with far less data than what’s available in podcasting currently, such as social media influencer marketing.
We need to shape the narrative about what makes podcasting unique. Right now excuses about what data we can’t get coupled with a very middle-of-the-road reporting suite from most hosts aren’t going to help us get to the next level.
Ideally, hosting platforms start providing more data with these mindset. I’d love to see more job openings for data scientists at hosting companies to help make that happen. But even if it doesn’t, podcast publishers have rights to all of this data and should start taking it into their own hands, especially if they are trying to differentiate themselves from their competitors.
If this was easy, I wouldn’t be writing articles about it. But it is accessible and it is how we get people to stop trying to turn podcasting into another channel and start respecting it for the unique strengths it brings.
We have so much unique data. Let’s start thinking smarter about how to use it.
Homework
Podcast adtech excites me on its own almost as much as teaching others about it does. This space is absolutely accessible to anyone who wants to learn, and it’s important to me not only to share my knowledge with you but to help you ask questions to further your own understanding. Below are some questions to think about after you’ve read the article, and to consider sending to any relevant partners you work with to get their answers.
Sounds Profitable will never charge our readers to learn from us, but several individuals have asked about supporting us directly. You can find out more about our individual sponsorship at our Patreon.
Publishers & Advertisers
- Do you fully understand your rights to data?
- Does your company have a standard data processing agreement?
- Are you equipped to take in raw data and gain insight from it?
- Have you made feature requests of your adtech partner for further data insights?
Adtech Partners
- Do you clearly define your clients’ rights to data?
- Is there an easily accessible process for your clients to request or access their data?
- Are you actively expanding your data science team to focus on more robust reporting?
New Sponsors
Support from our amazing sponsors is truly the only way that Sounds Profitable could exist. They provide me the means to stay completely independent, allowing me to fully write about all aspects of this industry without being bound to any one company. With that said, I’d like to introduce you to our latest two sponsors:
- Signal Hill Insights provides audio-focused adaptable research—a meaningful alternative to the old business model based on one-size-fits-all research products.
- Market Enginuity represents some of the most popular podcasts in the world and public media stations nationwide, fueling mission-driven, educational and inspiring independent media with innovative sponsorship strategies.
We appreciate the support of all our sponsors, so please take a look at the full list below. If I can make an introduction for you to any of the sponsors, please don’t hesitate to reach out!
If you’d like to learn more about sponsorship or advertising with us, just hit reply.
Market Insights – with ThoughtLeaders
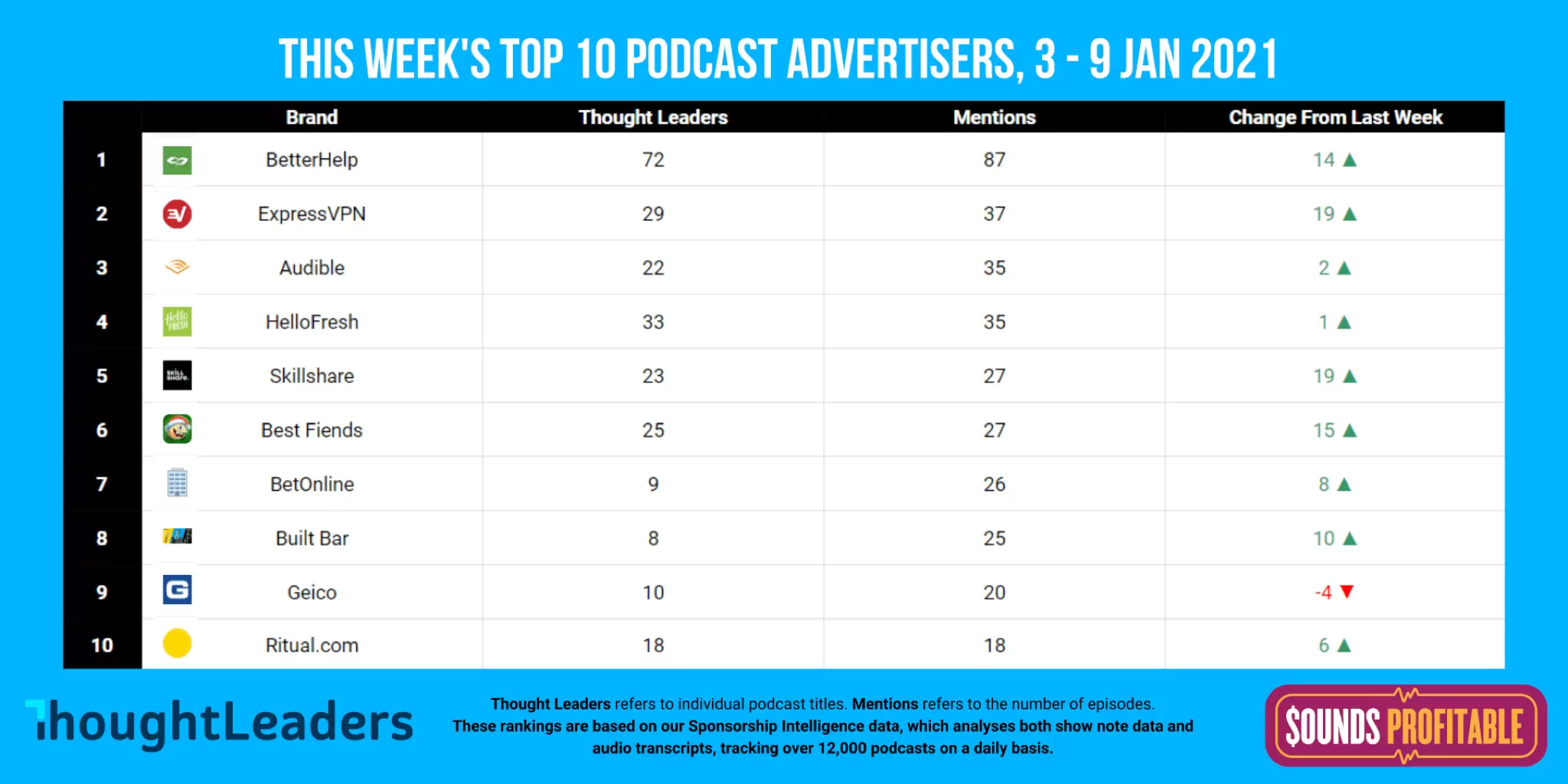
Comparing this week to last week, we’re seeing an increase in mentions, which makes sense as ad budgets renew. It’s also neat to see four new advertisers push their way into this list. Hit reply and let me know your thoughts.
Product Deepdives
Our Product Deepdives are a detailed walkthrough of podcast adtech products, who they’re for and how they actually work. Last month, we learned all about Podscribe for Advertisers, which you can watch on-demand for free.
On January 21st at 4pm ET, we’ll be premiering our January episode with where we’ll learn more about the Triton Digital Podcast Metrics product, including all the new features for advertisers. If you can’t make it for the live Q&A, we’ll have the video available on demand shortly after on Sounds Profitable.
Podcast Appearances
Last week I had the chance to join two great podcasts. Definitely check them out
- The Podcast Club (January 9th episode)
- Podland News (January 8th episode)
Things to Think About
I highly recommend all my subscribers also subscribe to Podnews. This week, I found two pieces of information that caught my attention.
- Jack Rhysider of Darknet Dairies dives into Megaphone ending up on multiple block lists. While this isn’t impacting a large number of listeners, it’s important to understand that these lists aren’t using tech to identify if the host should be blocked, they’re using privacy agreements and feature descriptions on their website. That means any hosting provider could end up on one of these lists in the future. If you’re a fan of Darknet Dairies and of James Cridland and I, please consider begging Jack shamelessly to do an episode on podcast privacy with us.
- Twitter acquired Breaker to expand TwitterSpaces. Do I have access to an early version of that?